What’s the difference between a Rust char and a Go rune?
Rust and Go have similar ways of dealing with UTF-8 encoded
text. Rust gives you the .chars() method on strings,
which returns a sequence of chars (no surprise). Go
on the other hand gives you []rune(str), which
returns a slice of runes. What’s the difference
between these two things?
The answer is that a char
is a Unicode Scalar Value, whereas a rune is
a Unicode Code Point. That is… not very helpful. What’s the
difference between those things?
A crappy but correct answer to this question is “a unicode scalar value is any unicode code point except high surrogate and low surrogate code points”. Ugh. You need a fair bit of context to understand this, so I will do my best to explain it from the beginning.
The unicode standard has the lofty goal of unifying the way that all possible characters are represented digitally. They do this by assigning a unique integer in the range 0 to 0x10FFFF to every single character. This unique integer is called a code point.1
This notion of code points is abstract – these are not necessarily what is stored on your computer. For this, we need some kind of agreed-upon scheme for encoding and decoding unicode text.
The naive solution is to just store these code points using a sufficiently large integer type. The largest possible code point is 0x10FFFF (1,114,111 in decimal), which can be represented using 21 bits. The smallest integer type that’s larger than 21 is u32, or four bytes. These 4 bytes are treated as a single unit called a code unit.2
This is actually a real encoding, called UTF-32. The downside of this encoding is that we suddenly need four bytes to represent most English text, which was previously only using a single byte (in ascii). This would mean that a 1GB ASCII text file would need 4GB if it was encoded using UTF-32. For this reason, there are other encodings that are more popular.
The most popular is UTF-8, which you have probably heard of. It uses between 1 and 4 bytes to represent any of the unicode code points. For UTF-8, the code unit is a single byte. Most text on the web is encoded using UTF-8. Upon encountering a byte, you can tell how many more bytes you’ll need to process to get your whole code point by seeing what range it’s in:
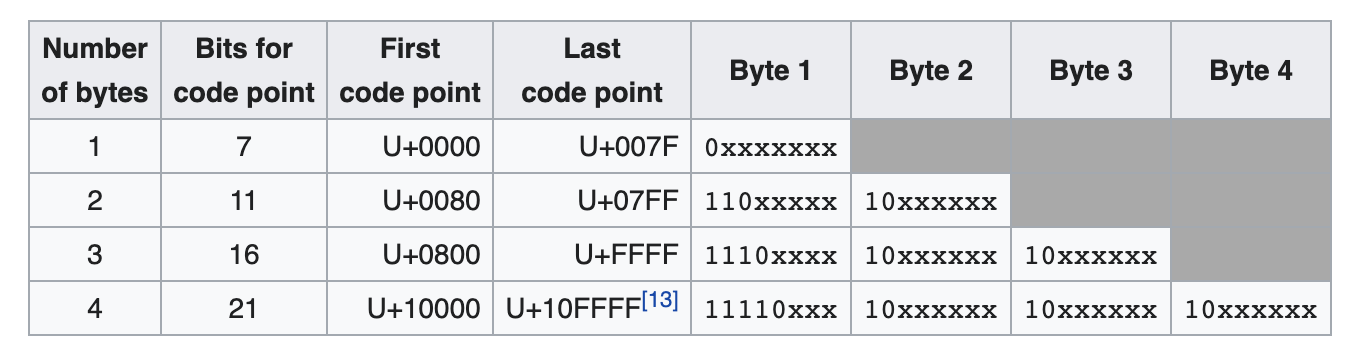
Another popular encoding is UTF-16, which uses two bytes as its code unit. Most code points can be encoded using a single code unit, but there are some that require two code units.
The code points that can be encoding using a single code unit lie in a range called the Basic Multilingual Plane (BMP).3 This includes all code points in the range 0 to 0xFFFF. Code points outside of this range are the ones encoded with two code units.
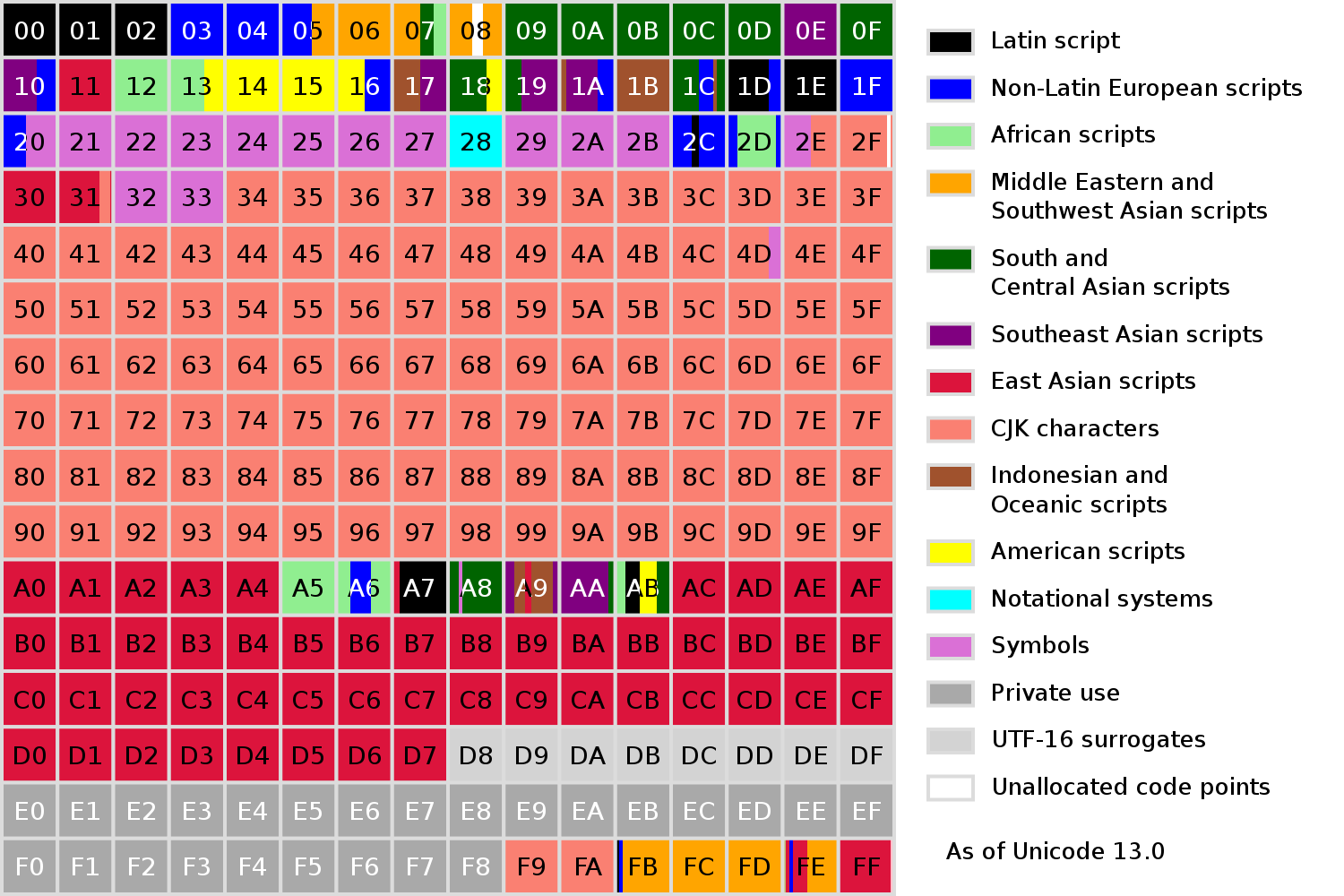
The two units used to represent a single code point are called a surrogate pair.4 The first unit in the pair is called the high surrogate, and the second unit is called the low surrogate. There is some well-defined transformation to get from a code point to a surrogate pair but the details of that transformation are not important for our purposes.
Each of the surrogates actually lies within the BPM! You can see them in the graphic above, in the range 0xD8 to 0xDF. So there is actually an artefact of the UTF-16 encoding in the unicode standard, which is sort of weird.
The fact that this artefact exists means that all environments have to deal with them some how. In the case of rust, it simply says that high and low surrogates are not valid chars. Hence, chars represent scalar values5.
What happens if you try and decode a high or low surrogate? Rust just tells you that it’s not a valid char:
fn main() {
// 0xD800 is the first high surrogate
let c = core::char::from_u32(0xD800);
println!("{:?}", c); // prints "None"
}Summary
- Unicode assigns a unique number to each possible character, called a code point
- There are several ways to encode these code points. UTF-16 is one of them
- 16 bits (the size of a UTF-16 code unit) is not enough to represent every code point, so pairs of code units are used
- These pairs are called surrogate pairs
- The code points used inside surrogate pairs only have meaning when they’re in a surrogate pair
- Unicode scalar values are all code points except surrogates
References
- https://stackoverflow.com/questions/48465265/what-is-the-difference-between-unicode-code-points-and-unicode-scalars
- https://doc.rust-lang.org/1.2.0/std/primitive.char.html
- https://blog.golang.org/strings
- https://www.unicode.org/glossary
- https://en.wikipedia.org/wiki/UTF-8
- https://en.wikipedia.org/wiki/UTF-16
A Code Point is “any value in the Unicode codespace; that is, the range of integers from 0 to 0x10FFFF”↩︎
A Code Unit is “the minimal bit combination that can represent a unit of encoded text for processing or interchange”↩︎
A Plane is “a range of 65,536 contiguous Unicode code points”↩︎
A Surrogate Pair is “a representation [of] a single abstract character [consisting of] a sequence of two 16-bit code units”↩︎
A Unicode Scalar Value is “any Unicode code point except high-surrogate and low-surrogate code points”↩︎